Incident Response Plan Template And Guide
In the high-stakes world of cybersecurity, grabbing a generic, off-the-shelf incident response plan feels like a quick win. But it’s not just insufficient—it’s a flat-out liability. Relying on a one-size-fits-all document creates a dangerous illusion of security.
True resilience isn’t about having a document that just checks a compliance box. It comes from a plan that’s been meticulously shaped around your company’s unique operational realities.
Table of Contents
Why A Generic Plan Is A Liability


I've seen it happen time and again: a company downloads a generic incident response plan template, fills in a few blanks, and considers the job done. This creates a false sense of preparedness that crumbles the moment a real crisis hits. During the chaos of a cyberattack, those vague instructions and placeholder roles leave your team confused and reactive when they need to be decisive.
This failure isn’t just theoretical; it has severe, real-world financial consequences. A well-structured, customized plan is one of the most powerful tools you have for mitigating damage.
The data backs this up. Organizations with a formal incident response team and a tested plan can slash the financial impact of a breach by a staggering 30% compared to those without one. With the global average cost of a data breach now sitting at around $4.35 million, the ROI on proper planning becomes painfully clear. You can dig into more data on the financial upside of incident response readiness on Palo Alto Networks' Cyberpedia.
The Perils Of A One-Size-Fits-All Approach
A generic plan can't possibly account for your unique business environment. It doesn't know which of your systems are mission-critical, what data is most sensitive, or who on your team has the specific expertise needed to shut down a threat. This ignorance leads to critical, and often disastrous, gaps.

Think about these common failures I see with generic plans:
- Undefined Roles: A template might list "IT Lead" or "Communications Manager," but it doesn’t name the actual person who needs to be woken up at 2 AM on a Sunday. It also doesn't define their specific duties, which leads to paralysis.
- Irrelevant Procedures: The plan could have detailed steps for containing a type of malware you don't even use or for securing a cloud platform your company ditched years ago. Wasted time is the last thing you need during an incident.
- Vague Communication Protocols: Simply stating "notify stakeholders" is utterly useless. Who are they? What do they need to know, and when? A customized plan defines these audiences and prepares the messages in advance.
A plan that hasn't been tested and tailored is merely a document, not a defense. It’s during a real-time simulation or—worse—an actual incident that you discover the document you relied on is full of holes.
Building Resilience Beyond The Template
The real purpose of using an incident response plan template isn't to adopt it as-is. Its value is as a foundation—a structured starting point that you build on, mold, and make your own. The goal is to move beyond simply having a plan to cultivating genuine organizational resilience.
This requires a fundamental shift in mindset. It’s not about checking a box or completing a document; it’s about empowering your team. A customized plan becomes a clear, actionable playbook that aligns perfectly with your specific technology stack, business priorities, and regulatory obligations.
When your team has a plan they helped build and have actually practiced, they can act with confidence and precision. This proactive approach transforms your plan from a static file into a living, breathing tool for survival. It minimizes costly downtime, protects your hard-won reputation, and ensures your business can withstand and recover from an attack, emerging stronger and more prepared for whatever comes next.
Your Incident Response Plan Template

A strong defense starts with a solid game plan. Let's be clear: a generic, one-size-fits-all document is a liability waiting to happen. But a well-structured incident response plan template? That's an invaluable strategic tool. It gives you the essential framework, making sure you don't miss the critical pieces as you build a plan that actually fits your organization.
Think of this template as a detailed blueprint, not a finished product. It’s built around the six globally recognized phases of incident response—a continuous cycle that guides your team from initial preparation all the way through to post-incident analysis. Getting a handle on this structure is the first step toward creating a plan your team can execute with confidence when the pressure is on.
To get a sense of the flow, here’s a quick look at how the core phases—detection, analysis, and containment—work together in a real crisis.
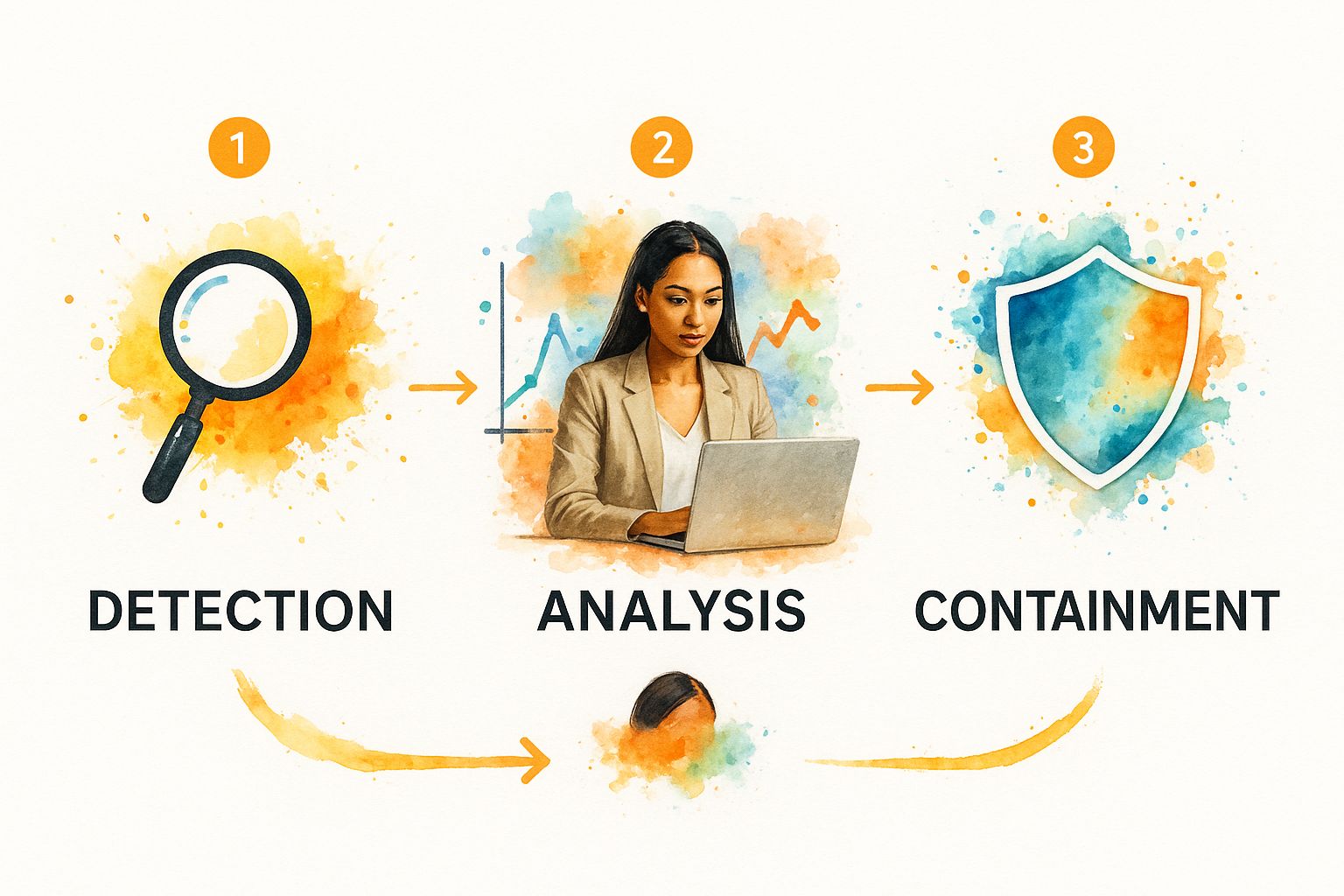

This visual really drives home that incident response is a fluid process, not just a linear checklist. You're constantly moving from identifying a threat, to figuring out its impact, and finally, stopping the spread.
The Six Phases Of Incident Response
Our template is organized to align perfectly with the incident response lifecycle first popularized by SANS and now adopted pretty much everywhere. Each section in the template maps directly to one of these phases, giving you a logical flow for both planning ahead and acting during an event.
-
Preparation: This is where the real work happens—long before an incident ever occurs. It’s everything from assembling your Computer Security Incident Response Team (CSIRT) to arming them with the right tools and running drills. It's all about building your defenses and making sure everyone knows their role when things go sideways.
-
Identification: How do you know you've been breached? This phase is all about detection and analysis. It lays out the procedures for monitoring your systems, spotting deviations from normal activity, and then quickly confirming if an alert is a false alarm or a genuine security incident.
-
Containment: Once you've confirmed an incident, the immediate priority is to stop the bleeding. The containment phase details your strategies for isolating affected systems to prevent an attacker from moving laterally and causing more damage. This might be a short-term fix, like yanking a server off the network, or it could involve longer-term solutions to rebuild clean systems.
-
Eradication: After you've contained the threat, you have to get it out of your environment completely. This is where you find the root cause—how they got in—and systematically remove every trace of the attacker's presence. The goal here is to ensure the threat is gone for good.
-
Recovery: With the threat gone, it’s time to safely get things back to normal. This phase guides you through restoring affected systems, usually from clean, secure backups, and then monitoring them closely to make sure there's no reinfection. The objective is to return to business as usual with as little disruption as possible.
-
Lessons Learned: This is the final, and arguably most important, step that happens after every single incident. Your team needs to conduct a post-mortem to analyze what happened, what went right, what went wrong, and how the response plan itself can be improved.

An incident response plan that skips the "Lessons Learned" phase is doomed to repeat its mistakes. This step turns every incident, big or small, into an opportunity to strengthen your security posture for the future.
Core Template Components You Will Find

Beyond just the six phases, our incident response plan template includes the essential sections that form the operational core of your strategy. We’ve dedicated space for defining key elements that are so often overlooked in those generic, check-the-box documents.
You'll find these critical components baked right in:
- Roles and Responsibilities: This clearly defines who is on the response team and what they do, from the Incident Commander making the tough calls to the legal counsel and communications leads managing the fallout.
- Communication Plan: It outlines the exact protocols for internal and external communication. This includes who to notify, when to notify them, and what information to share—a critical step for managing chaos and meeting regulatory deadlines.
- Incident Classification: This gives you a framework for scoring incidents based on their severity and business impact, which is crucial for prioritizing your team's efforts when multiple things are on fire.
Each of these sections serves a distinct purpose, transforming the template from a static document into an actionable playbook. This structure ensures your team has the clear guidance it needs to navigate the confusion and pressure of a real security incident.
An incident response plan template is a great starting point, but it's not the finish line. Think of it like a blueprint for a house—it gives you the structure, but you’re the one who has to pick the paint, place the furniture, and install the security system. To be truly effective when a crisis hits, that generic document needs to become your playbook, reflecting the reality of how your business actually works.

This is where the real work begins. We need to move from abstract ideas to concrete actions and assign real people to critical roles. An incident isn't just an IT problem; it's a business crisis that can touch every corner of your organization.
Building Your Cross-Functional Response Team
A response plan that only involves your tech team is doomed from the start. When a breach happens, the fallout goes way beyond servers and data. You’ll be dealing with potential legal issues, urgent customer communications, and sensitive HR matters. That's why your core incident response team has to include people from across the business.
Your first job is to map these essential roles to specific individuals in your company:
- Incident Commander (IC): This is your quarterback, the ultimate decision-maker during a crisis. Often a CISO or IT Director, this person has the final say on critical actions, like taking a system offline to stop an attack.
- Technical Lead: The hands-on investigator. They’re deep in the weeds, figuring out what happened, how to stop it, and how to kick the threat out of your network. This role is all about digital forensics and system recovery.
- Legal Counsel: You need legal advice from the very beginning. They’ll guide you on regulatory notifications (like for HIPAA or the FTC), manage potential liability, and make sure evidence is preserved correctly.
- Communications Lead: This person owns the narrative. They manage all messaging—to employees, customers, regulators, and sometimes the media—to maintain trust and control the story.
- Human Resources Lead: If employee data is involved or an insider is the cause, HR is critical. They handle internal communications and navigate any personnel issues that arise.
- Business Unit Leaders: You need input from the heads of departments like finance, operations, or product. They are the only ones who can truly tell you how an outage of a specific system will impact the business's bottom line.
A common mistake I see is companies scrambling to figure out who's on the team after an incident starts. By then, it’s too late. Defining these roles and responsibilities now eliminates confusion and lets your team act immediately when every second counts.
Customizing Your Plan for Specific Threats
A ransomware attack and a quiet data leak from an insider are two completely different animals. Your response shouldn't be a one-size-fits-all procedure. The best incident response plan templates include separate playbooks or annexes for the threats you’re most likely to face.
Let’s walk through two scenarios to see why this matters.
Scenario 1: Ransomware Attack
Your monitoring tools scream that ransomware is actively encrypting files on a critical server. The playbook for this is all about speed and containment. The Technical Lead immediately works to isolate that server and connected network segments. The Incident Commander is on a call with the Business Unit Leaders to assess the impact of taking it offline. At the same time, the Communications Lead is already drafting a message to employees about potential system downtime, while Legal Counsel is advising on the tough question of whether to even consider paying a ransom.
Scenario 2: Customer Data Leak
Here, an analyst discovers that a database full of customer PII was accessed by an unauthorized account several weeks ago. The active threat is gone, so the immediate priority shifts from containment to investigation. The Technical Lead dives into logs to figure out exactly what data was taken. The response becomes heavily focused on compliance and communication. Legal and Communications work hand-in-hand to draft breach notifications that meet strict requirements from regulations like GDPR, HIPAA, or state laws.
By creating these distinct workflows, you give your team a clear, step-by-step guide they can follow under immense pressure, instead of wasting precious time trying to adapt a generic plan on the fly.
To get you started, here is a practical checklist for the most important customizations you need to make. Think of this as your guide to turning our template into a plan that’s truly yours.
Core Template Customization Checklist
| Customization Area | Key Action | Example |
|---|---|---|
| Roles & Responsibilities | Assign specific individuals and at least one backup to each core team role. | Incident Commander: Jane Doe (IT Director) Backup: John Smith (Security Manager) |
| Critical Asset Identification | List your most important systems, data, and applications and rank them by business impact. | The customer relationship management (CRM) system is a Tier 1 asset because it holds PII and is essential for daily operations. |
| Escalation Paths | Define clear triggers for when to notify executives, legal, or external partners like cyber insurance. | Any confirmed breach of a Tier 1 asset automatically triggers escalation to the CEO and Legal Counsel within one hour. |
| Communication Plans | Draft pre-approved message templates for different scenarios and audiences. | Have separate, ready-to-go notification templates for internal employees, affected customers, and key regulators. |
Once you’ve worked through these key areas, your incident response plan will go from a simple document to a powerful tool that can genuinely guide your team through a crisis. It’s an investment of time upfront that pays for itself the first time you have to use it.
An incident response plan that sits on a shelf is useless. One that ignores regulations is a liability. It's one thing to have a plan for when things go wrong, but it’s another thing entirely to make sure that plan will stand up to the scrutiny of an auditor.
Regulations from bodies like NIST, HIPAA, and the FTC aren't just suggestions—they come with serious penalties. Your incident response template gives you a solid framework, but the real work is in translating those dense legal requirements into practical, actionable steps your team can actually follow in a crisis.
Think of it this way: your plan needs to work for your team at 2 a.m. on a Saturday, and for a regulator on a Monday morning. Let's break down how to make that happen.
Translating NIST Guidelines Into Action
If you're wondering where to start with compliance, the National Institute of Standards and Technology (NIST) is the answer. Their frameworks are the bedrock that many other regulations are built on. Following NIST isn't just about checking a box; it’s about adopting a structured, repeatable process for handling security incidents.
Many organizations lean on NIST's Special Publication 800-61r2, a globally recognized 79-page guide for building an incident response capability. It’s the gold standard. Using a template based on its principles, as outlined in Exabeam's detailed overview, is a smart move for building a resilient and compliant program.
To bake NIST's principles into your plan, focus on these key areas of your template:
- Preparation: This is where you document your team's training, the tools you have ready (like SIEM or EDR), and your security policies. NIST is big on being ready before an incident happens.
- Detection & Analysis: How do you spot an incident? What defines an "incident" versus a minor event? Detail your monitoring processes and the tools you use to investigate.
- Containment, Eradication & Recovery: Your template should have distinct procedures for each of these phases, mapping directly to the NIST lifecycle. This means clear steps for isolating systems, killing the threat, and safely bringing everything back online.
- Post-Incident Activity: This is critical for NIST. Your plan must have a dedicated "Lessons Learned" section. Document what happened, what went right, what went wrong, and what you’ll do to improve next time.
Addressing HIPAA Breach Notification Rules
For any business that touches protected health information (PHI), HIPAA isn't just a guideline—it's the law. The HIPAA Breach Notification Rule has incredibly specific requirements that need to be hardwired into your response plan. A generic "notify stakeholders" checklist won't cut it.
The moment a breach involving PHI is suspected, a regulatory clock starts ticking. Without a pre-defined HIPAA workflow in your incident response plan, you risk missing critical deadlines, leading to hefty fines and reputational damage.
Here's how to embed HIPAA requirements directly into your incident response plan:
- Immediate Risk Assessment: Your plan must trigger a formal, documented risk assessment to determine if PHI was compromised. This is a non-negotiable first step under HIPAA.
- Strict Notification Timelines: Spell it out. Individuals must be notified "without unreasonable delay" and no later than 60 calendar days after discovery.
- HHS Notification Protocol: For breaches affecting 500 or more individuals, the plan must require immediate notification to the Secretary of Health and Human Services. For smaller breaches, specify that they must be logged and reported annually.
- Media Notification Requirement: If a breach affects more than 500 residents in a single state, your plan must include a step to notify prominent media outlets in that area.
Complying With The FTC Safeguards Rule
If you're a financial institution—and this includes a lot more than just banks, like mortgage brokers and tax preparers—the FTC Safeguards Rule applies to you. It mandates a written information security program, and a core piece of that is your incident response plan.
The FTC's main concern is protecting consumer financial information. Your plan needs to show exactly how you detect, respond to, and recover from events that put this data at risk. As you align with regulations, it's also a good time to ensure your internal practices match your public promises, which often involves understanding your organization's privacy policy.
To meet the FTC's requirements, your plan needs to explicitly document:
- Designated Coordinator: The FTC requires you to name a specific employee to coordinate the entire information security program. This person's name and role should be right there in the plan.
- Threat Identification and Assessment: Your plan should describe the processes you use to monitor for and identify "reasonably foreseeable" threats to customer data.
- The Response Program: The plan itself is the main requirement. It must clearly define the goals of the response, the processes for fixing the problem, and who is responsible for what.
- Post-Incident Evaluation: Just like with NIST, you have to show you're learning. The plan must detail how you will evaluate your response after an incident and make necessary improvements.
How To Test And Maintain Your Plan

An incident response plan template is a fantastic starting point, but let's be real: an untested plan is just a theory on paper. In a real crisis, you don't magically rise to the occasion; you fall back on your training. This is where the real work begins—testing and maintaining your plan is how you build actual defensive muscle.
Without regular "fire drills," your team’s familiarity with the plan will fade fast. Roles get fuzzy, technical steps become outdated, and the confidence needed to act decisively evaporates. Regularly testing your plan is a critical part of any solid risk management strategy, for-profit or not, and it's one of the most effective nonprofit risk management tips you can implement to protect your mission.
Validating Your Plan With Realistic Testing
Testing isn’t about passing or failing. It’s about finding the cracks in your armor in a safe environment before an attacker finds them for you. The whole point is to simulate the pressure of a real event and see how both your plan and your people hold up.
There are a few great ways to do this, from simple conversations to full-blown simulations.
- Tabletop Exercises: This is the best place to start. Get your incident response team in a room and walk through a prepared scenario. A facilitator describes an event—maybe a phishing attack that led to credential theft—and each team member explains exactly what they would do, step-by-step, according to the plan.
- Functional Drills: These are more hands-on. Instead of just talking, you test a specific part of your plan. For example, can your tech team actually restore critical data from backups within your target RTO? Can your communications lead actually use the emergency notification system to send an alert?
- Full-Scale Simulations: This is the most immersive test you can run. It mimics a real incident from start to finish, involving everyone on the team and maybe even external partners. You might have a "red team" of ethical hackers actively trying to breach your defenses while your "blue team" (your defenders) uses the plan to stop them.
An untested plan is a source of false confidence. It's only through practice that stakeholders truly grasp the response strategy and develop the muscle memory needed for real-world cyber resilience.
Conducting Effective Plan Reviews
After every test—or, unfortunately, after every real incident—the "Lessons Learned" meeting is non-negotiable. This is your chance to turn hard-won experience into meaningful improvement. It must be a blameless discussion focused on one thing: making the plan better.
Here are the critical questions you need to ask during the review:
- What parts of the plan worked exactly like we thought they would?
- Where did we have to go off-script? Why?
- Were there any communication breakdowns, either internally or with customers?
- Did everyone on the team clearly understand their role and what was expected of them?
- Did our security tools actually help us detect and respond effectively?
The answers become your action items for updating the plan. Did you find out a key vendor's contact number was wrong? Update it. Was a procedure too clunky or confusing under pressure? Refine it. This continuous feedback loop is what transforms a static document into a living, effective defense.
Creating A Maintenance Schedule
Your plan will go stale faster than you think. New threats pop up, team members change jobs, and your tech stack is constantly evolving. To keep your plan sharp and relevant, you need a proactive maintenance schedule.
Here’s a realistic framework to get you started:
| Frequency | Task | Owner |
|---|---|---|
| Quarterly | Review and update all contact lists and vendor information. | Incident Commander |
| Semi-Annually | Conduct a tabletop exercise with a new, relevant scenario. | Security Manager |
| Annually | Perform a full review and update of the entire plan, incorporating all minor changes and lessons learned from the year. | Incident Commander |
| As Needed | Update the plan after any significant organizational or technology change (e.g., new cloud provider, office move, team restructuring). | Relevant Team Lead |
A structured approach like this ensures your incident response plan never gathers dust. It remains a reliable tool that empowers your team to handle a security breach with confidence and precision, minimizing damage and protecting your business.
Common Questions About Incident Response Plans
Even with a detailed guide in hand, it’s completely normal to have questions when you start digging into incident response. Honestly, it's a good sign. Building a truly resilient defense means getting curious and making sure every part of your strategy is clear, practical, and ready for a real-world test.
Let’s tackle some of the most frequent questions we hear from organizations as they go from a generic incident response plan template to a fully customized, battle-ready playbook.
How Often Should We Test Our Incident Response Plan?
This is easily one of the most important questions, and the answer isn't just a number—it’s about building a culture of readiness. At an absolute rock-bottom minimum, you need to run a comprehensive tabletop exercise annually. This keeps the core concepts fresh and makes sure everyone on the team actually understands their role when things go sideways.
But the organizations that handle crises best? They go further. The real sweet spot is more frequent, focused testing. We recommend holding smaller, functional drills on a quarterly basis. For example, one quarter you could test your data recovery procedures from backups. The next, you could run a drill on your external communication protocols to see how your PR and legal teams hold up.
A plan that’s only dusted off once a year is already out of date. The goal is to weave incident response into the living fabric of your operations, not have it be some forgotten file you’re frantically searching for while alarms are blaring.
Frequent testing also ensures your plan evolves with your business. Any time you make a significant change—like bringing on a new cloud provider, launching a major piece of software, or restructuring a team—it’s smart to revisit and test the parts of your plan that are affected.
What Is The Single Biggest Mistake Companies Make?
The most common—and costly—failure we see is the "set it and forget it" mindset. It happens all the time. A company invests a ton of effort to create the initial document, gets it approved, and then proudly files it away to check a box for compliance. They don't look at it again until a disaster strikes.
By that point, the plan is virtually useless. The contact list is full of people who left the company years ago, the technical procedures no longer match the current environment, and the people assigned to key roles have no idea what they’re supposed to do. An effective plan isn't a static document; it’s a dynamic program that you have to actively maintain.
A successful program is built on:
- Regular Testing: Running drills to find the weak spots before an attacker does.
- Continuous Updates: Revising the plan after every test and every real incident.
- Cultural Integration: Making preparedness a shared responsibility across the company, not just an "IT thing."
Without that commitment, your plan is just a piece of paper that offers a false sense of security. And that's a dangerous thing to have when the pressure is on.
Who Should Be On The Response Team Besides IT?
An incident response team that only has IT and security people on it is a team that’s set up to fail. A cyberattack isn't just a technical problem; it’s a full-blown business crisis. The shockwaves hit every part of the organization—legal, financial, and reputational—and you need experts from those areas at the table from the very beginning.
A cross-functional team is absolutely essential. Beyond your technical wizards, your core team must include:
- Legal: To steer you through regulatory obligations, liability issues, and evidence preservation.
- Communications/PR: To manage the story, control rumors, and maintain the trust of your customers and stakeholders.
- Human Resources: To handle all the people-related issues, especially if an insider is involved or employee data gets compromised.
- Key Business Leaders: To make the big calls, like taking a critical system offline, and to assess the financial and operational impact of every decision.
With this diverse team, you ensure every angle of a breach is managed professionally. Legal contains the regulatory fallout, PR protects your brand, HR manages internal chaos, and business leaders make sure the response actions align with company priorities.
Does A Small Business Really Need A Formal Plan?
Yes. Absolutely. Without question. This might be the most dangerous misconception out there. Attackers love targeting small and medium-sized businesses for one simple reason: they assume these companies have weak defenses and no practiced response plan. SMBs are seen as the low-hanging fruit.
For a small business, a security incident isn't just another problem to solve; it can be an existential threat. You don't have the massive resources of a Fortune 500 company, so the costs of downtime, data recovery, and reputational damage can be completely devastating.
A formal plan is your roadmap to survival. It forces you to deploy your limited resources in the most effective way possible during a high-stress, chaotic event. This isn't about creating bureaucracy—it's about giving your small team the structure and clarity they need to make smart decisions when everything is on the line.
Navigating cybersecurity and compliance can be complex, but you don't have to do it alone. tekRESCUE provides end-to-end technology solutions, including robust incident response planning based on NIST, HIPAA, and FTC standards. Protect your business and build true resilience. Learn more about our approach at mytekrescue.com.
Table of Contents